医療系リアルワールドデータを用いた研究は、データ前処理が8割を占めると言われています。
そのため、「データ前処理にはプログラミング技術を用いる必要があり、手間も時間もかかる」というのが世間の常識です。
データの前処理の分野で、下記のような悩みをお持ちではないでしょうか?
1.リアルワールドデータの前処理に何時間も、エンジニアに頼んでも時には何日もかかることがある
2. データ前処理はエンジニア(あるいは外注として)に頼んでおり、コストがかかっている
3. 医療系のコンサルティングをしているが、顧客の要望を実現できない、あるいは理解できないことがある
私の発明は、データ前処理のためにプログラミングする必要がありません。データ前処理の負荷を大幅に減らす」ことができます。
下記に、支援内容について記載しています。
ご興味お持ちの方は、問い合わせページからご連絡ください。
根本的なアイデア
私の研究内容のイメージをご覧ください。
下記のような自動解析システムは原理的に実現可能です。

多くのシステムでは、データセット作成のためにはプログラミング作業が必要になります。
個々の利用者(研究者)により、作成したいデータセットが異なるからです。
このような理由から、すべての(ほとんどの)研究案件に対応するためには逐一システム改修が必要となります。
しかし、逐一プログラミングで関数などを実装するという運用ではコストパフォーマンスが低くなってしまいます。
そこで、私が提唱するシステムでは、システム改修の際にプログラミングを行う必要がありません。
その代わりに、データウェアハウス(データベース)を改修することで済ませることができます。
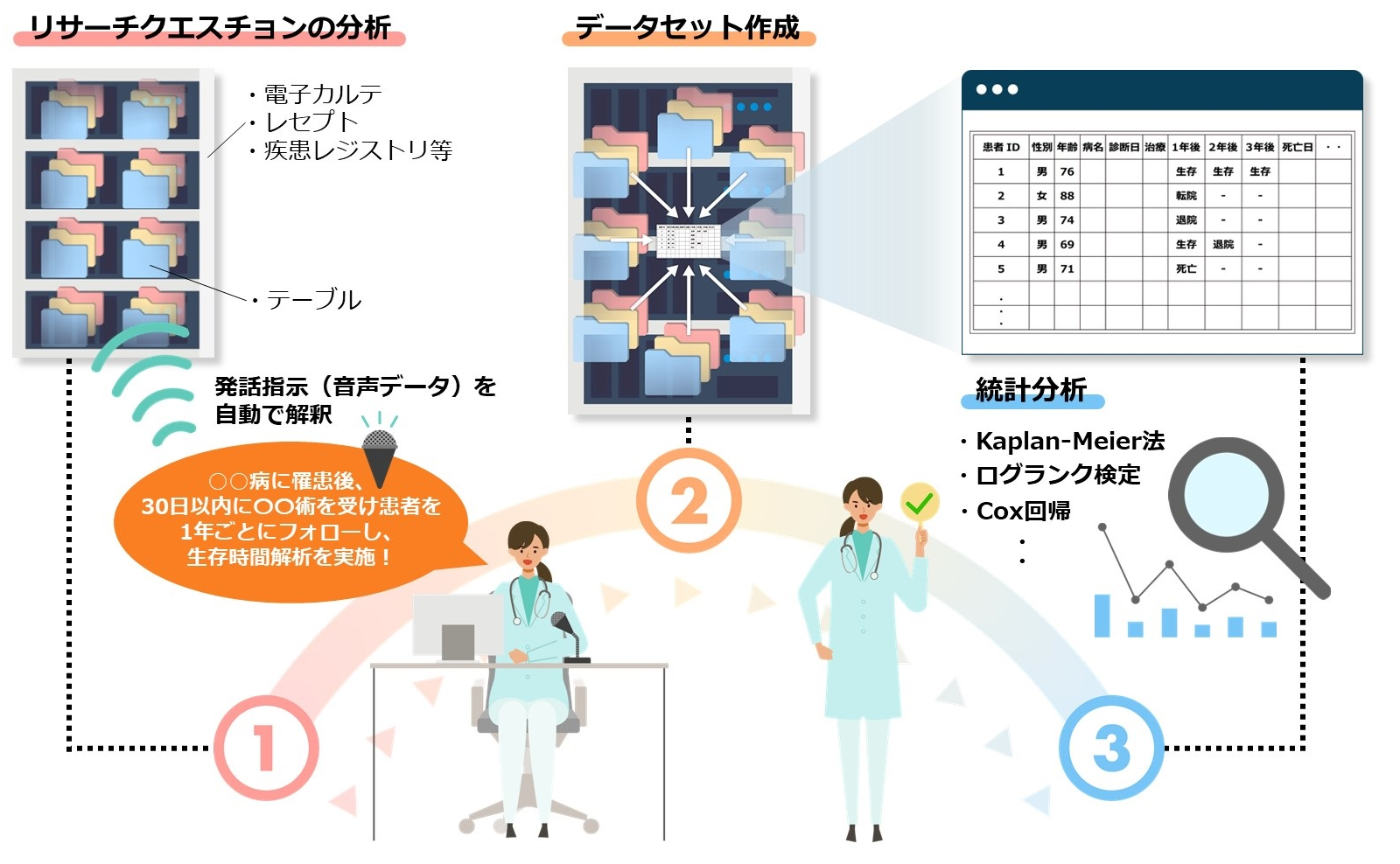
1. リサーチクエスチョンの分析
古典的なやり方ですが、下記の方法で実現可能です。
- マイクを経由して音声認識ソフトを用いて利用者のリサークエスチョンを文章ファイルとして取り込む
- 文章を常にポーリングしておき、それらを形態素解析して分解する
- 分解された単語を、次段階のデータセット作成工程を担うソフトウェアに送信する
2. データセットの作成
この工程では、前工程で得られた「傷病名」や「医薬品名」、「処方年月」等の文言を利用して患者ごとのデータセットを作成します。データセット作成手法に関しては、下記の研究成果にすべて記載しています。
A methodology of dataset generation for secondary use of health care big data: Kyoto University 1-80 2020. https://repository.kulib.kyoto-u.ac.jp/dspace/handle/2433/253411
3. 統計分析
前工程により、患者ごとのデータセットが構築されているため、すべての変数が確定されています。そのため、これらの変数を用いて所望の統計解析を自動的に行うことは比較的容易です。例えば、「傷病名」や「処置」、「医薬品」が確定されていますので、決め打ちで年齢や性別でχ二乗検定を行うなどが考えられます。
一方で、機械学習を使う方法も考えられます。システム構築後に医学研究が蓄積されていくにつれて「変数」と「解析手法」のパターンが蓄積されてきます。例えば、データセットの中に変数として「死亡日」が存在し、医薬品に「抗がん剤」が存在する場合、生存時間解析を用いることが多いという情報が学習モデルに反映されるでしょう。このような方法で自動解析システムを進化させていくことが可能です。
上記の説明はあくまでイメージですが、私は「2. データセット作成」を専門としています。
その部分だけ切りだして価値提供する方法が様々ありますので、そのバリエーションについてお示しします。
提案
根本的に、私の研究成果をお伝えするという意味では、同じです。前項で説明した成果がどのように提供できるのかについて、いくつかバリエーションがあります。
① 製薬企業、CRO様向けの支援
例えば自社で疫学用データベースを運用されており、市販後調査などを実施していた場合、その解析作業にどの程度かかっているでしょうか。本手法を適用すれば、特にデータ前処理作業において大幅に時間短縮できる可能性があります。
➁ IT系企業様向けの支援
企業や病院向けの案件で、電子カルテやレセプト等のデータウェアハウスを構築する際にコンサルタントとして支援いたします。解析に適したデータウェアハウス、あるいは解析システムを構築する際にプロジェクトに参加する形でお手伝いします。その際の支援内容としては、下記の「典型的な支援内容」の項目で説明しています。
③ 研究者向けの支援
私が持っている大規模データベースから患者ごとのデータセットを構築するノウハウをすべてお伝えいたします。
研究者の場合、データ抽出したデータを扱うことが多いと思います。この場合、抽出済のデータに対してデータウェアハウスを構築します。その後、下記の「典型的な支援内容」の手順2に記載されている検索アルゴリズムについて理解を深めていただき、ご自身で自在に扱えるようにしていただきます。
④ エンジニア向け支援
フリーランス等で医療系リアルワールドデータの分析を業務とされている方を対象として支援いたします。例えば、電子カルテやレセプト等で毎回使用するデータベースが決まっている場合には、本手法は非常に効率が良いです。一旦データウェアハウスを構築してしまえば、その後は単純な作業で多くの研究をカバーするデータセットをつくることができます。PythonやR等を用いてデータセットを作成されており、データ容量が大きくなり処理時間が膨大となりお悩みの方はぜひお声かけください。本手法を適用するだけで、プログラミングする局面は極めて少なくなります。
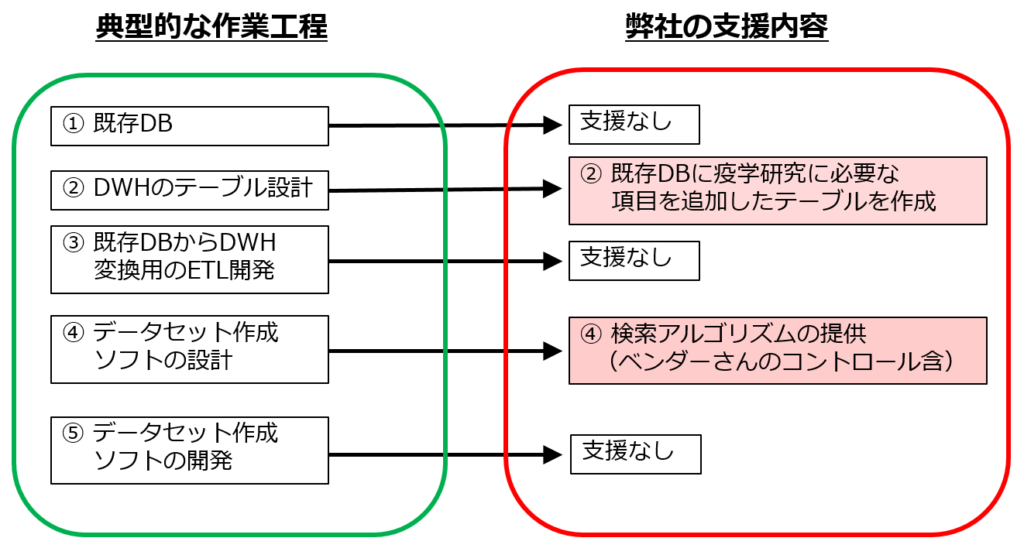
典型的な支援内容
典型的な支援内容を下記に示しました。
手順1. データウェアハウスの構築
既存のデータベース(組織で管理されているデータベース、あるいは特定のデータベースから抽出したデータ)を対象に、解析用のデータウェアハウスを構築します。データウェアハウスいう呼び名は大げさですが、既存データベースを少し変更したデータベースとお考えください。
手順2. 解析用データセット作成ソフトの開発
手順1で構築したデータウェアハウスをソースとして、データセット構築ソフトを構築します。検索アルゴリズムとして、数理論理学を応用したアルゴリズムを使用します。
基本的に、GUIが充実したWindowsプログラミング環境で開発することをおすすめします。
典型的な作業工程をお示しします。
期待される効果
本システム導入直後は、依頼者様が期待する研究の70パーセント程度がカバー可能です。10人の利用者のうち、7人程度の研究デザインはこのシステムを用いてデータセットを構築できるといった感覚です。
その後、本システムで実現できなかった研究事例を蓄積しておき、タイミングを見計らってデータウェアハウスを改善することで、最終的には90パーセント以上の研究をカバーすることができます。
コメント